Alterra.ai FAQ Editor
Alterra Answers is a bot that answers questions – about your products, about your company. It converts your static FAQ files into an intelligent question answering system. It appears in a widget on your website.
Powered by an artificial neural network, the system requires a training corpus of historic user queries with the correct answers assigned to them.
FAQ Editor helps you to
- Compose and edit your FAQ file or
- Upload your existing FAQ file and
- Upload and label your training corpus
Though Alterra Answers may appear similar to FAQ search, technically, it is not a search engine. It goes beyond searching for keywords in the FAQ files. It finds the right answer by analyzing historic user questions. Thus, you may keep the answers short and to the point. The bot will still find them, even if there is no keyword match.
On the other hand, it’s important to upload as many historic user queries to the system as possible. The bigger the training corpus, the higher the search quality.
Alterra Answers keeps a log of user queries it receives. With FAQ Editor you may peruse these queries, label them and add them to the training corpus.
After finishing editing and labeling, click on the Train link – the Machine Learning system will ingest the newly added training data, and re-learn.
Learn more about how to create, train, and launch your bot from our getting started guide.
FAQ Editor has three tabs:
- Edit: edit the FAQ file
- Label: label historic queries
- Settings
Edit tab
Use the Edit tab to compose and/or edit your FAQ file.
You may compose your FAQ file right in the Edit tab or copy-paste from your existing FAQ file line-by-line. You can also upload the entire existing file. You may then edit it in the Edit tab.
A typical FAQ file is a set of one question – one answer pairs.
However, users ask questions in their own words. Many of these questions are logically equivalent and shall be answered by the same answer. They are all paraphrases of one canonical question. That is, in real life, it shall be many equivalent questions – one answer. These paraphrase questions are stored in the system and used for training AI.
You may enter these paraphrase questions in the Edit tab. Click on the down arrow next to QUESTION and start typing.
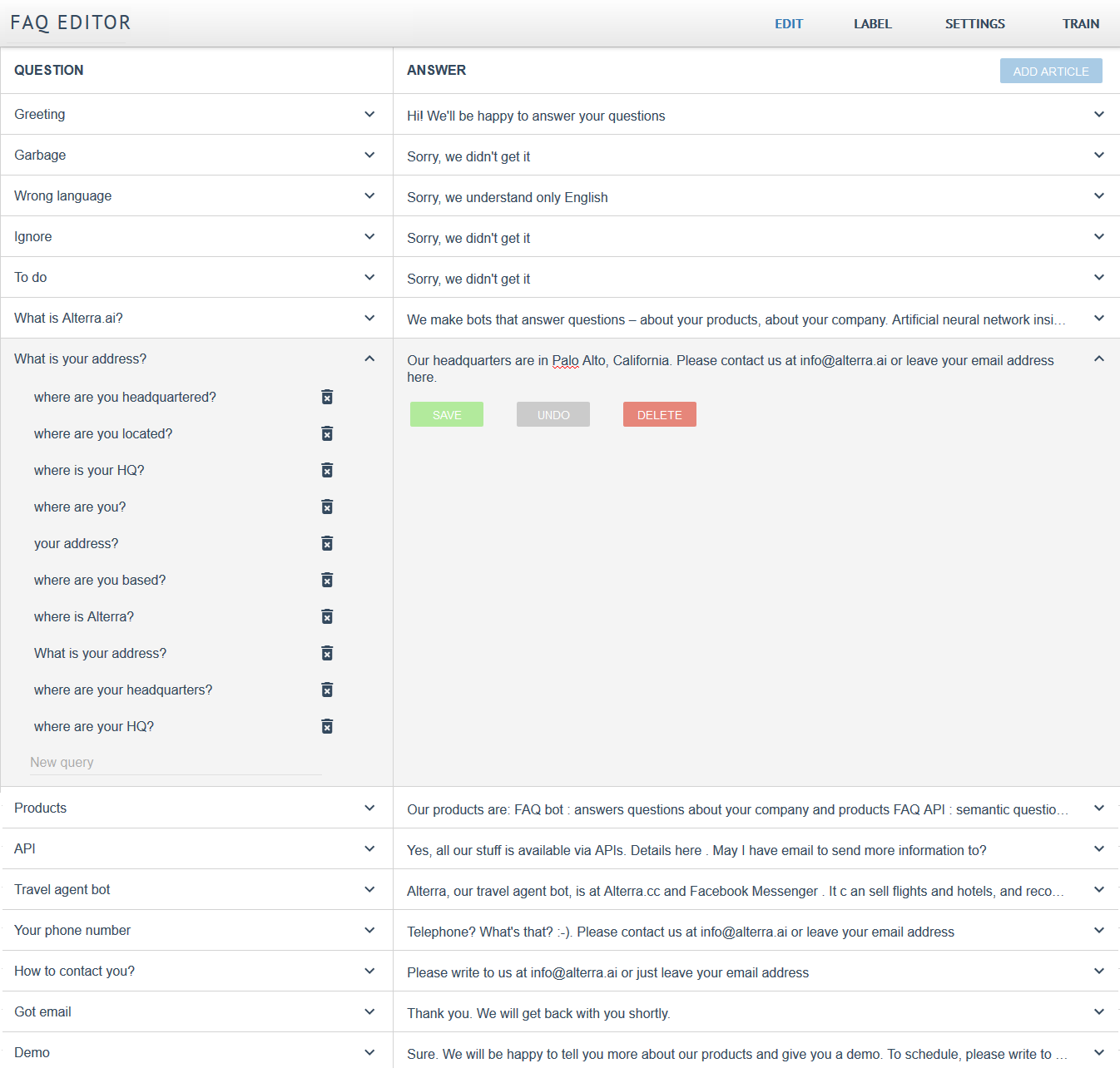
These paraphrase questions may be actual questions asked by actual users. You may copy-paste them from your logs or other sources. Alternatively, you may think them up. Think how you could rephrase the canonical question.
You may include rich text (HTML) in your answers. Copy-paste it from an HTML or rich-text file. The bot will display the rich text in the web widget.
Note that the main question in the question-answer pair is not indexed. Only the paraphrase questions in the drop-down list are indexed. However, when you enter a new canonical question it is automatically copied to the paraphrase list. If you want it indexed, keep it there. Otherwise, delete it.
This way, you may make the canonical questions short and easy for you to remember. It would become more of a FAQ article title. However, if it is not a legitimate frequently asked question you may exclude it from indexing. This way, it will not skew the search algorithms.
Label tab
Use the Label tab to label historic user queries.
Alterra Answers keeps a log of user queries it receives. You may peruse and label these queries in the Label tab.
Select one query in the Query Log column on the left. The search engine will display the answers it thinks are the correct answers, ranked by relevancy. They may be correct or not. Select the correct result. It will be forever recorded. The system will learn the correct answer from you and won’t make the mistake again.
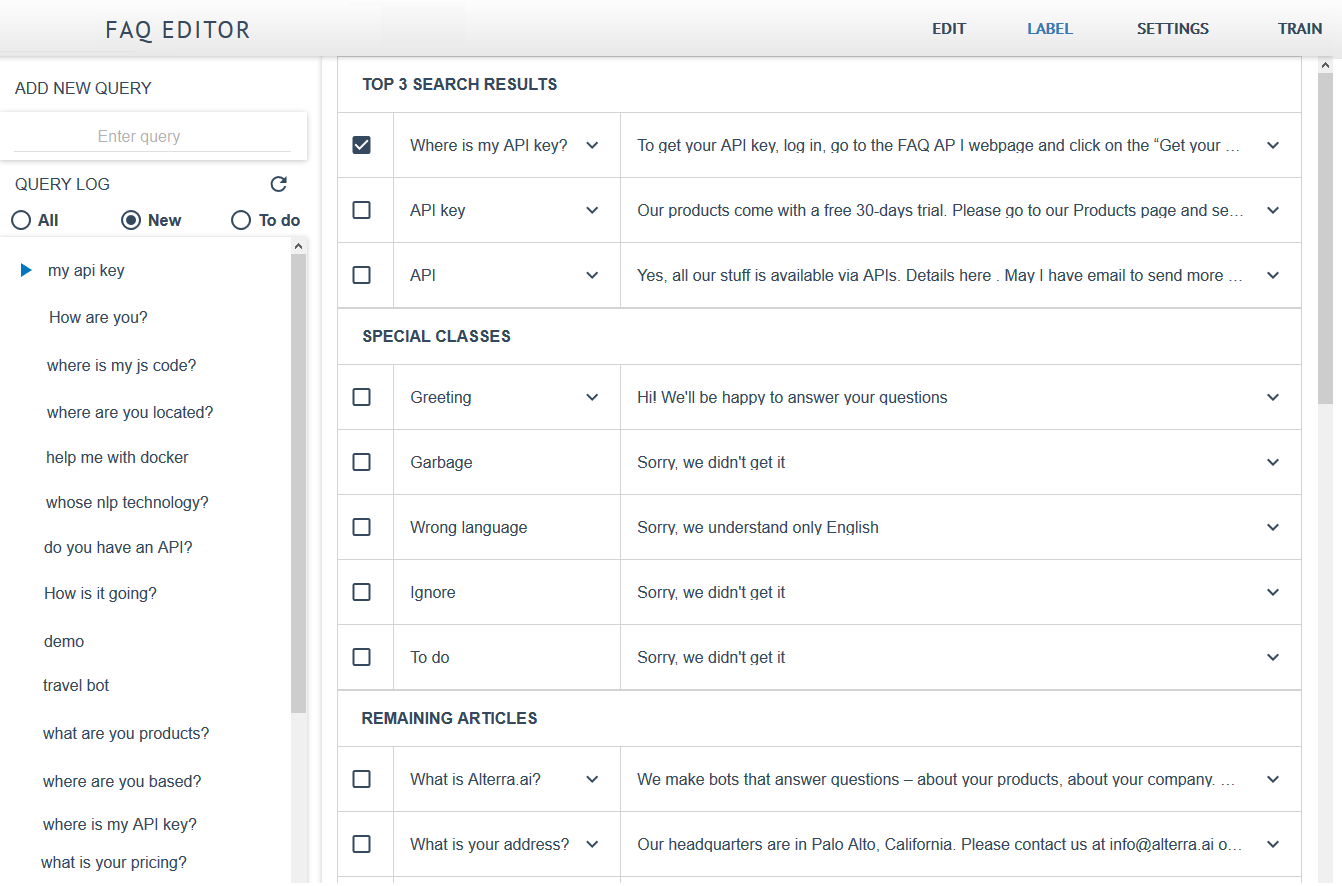
Even if the first search result is the correct one, still select it, to confirm. The AI learns from your feedback.
In addition to labeling actual user queries, you may come up with queries of your own, and label them, too. Just type your query in the ADD NEW QUERY box, and then select the correct answer.
After finishing labeling, click on the Train link – the Machine Learning system will ingest the newly added training data, and re-learn.
With the three radio buttons on top of the query log you may select
- All queries
- New not yet labeled queries
- To-do queries
- To-do queries
Normally, you should be interested in the New queries. Those are the ones you have not seen and labeled.
“To do” is a special case. They are like flagged/starred email. You’ve seen them before but did not label them then. You left them for the future. They are still waiting to be labeled. It’s your to-do list.
Special cases
Not all user queries shall be added to the training corpus. Some shall be discarded. To process them, there is a number of pre-defined classes:
| Title | Description |
|---|---|
| Wrong Language | The user query is not in English |
| Garbage | Completely useless queries. Garbage. Trash. Spam. Not worth answering, ever. |
| Ignore | Meaningful queries worth answering that however shall not be added to your FAQ file: off-topic, one-off, too ambiguous, too short, too long and complex for bot, requiring a non-public answer, etc. You may forward them to humans. |
| To do | Meaningful on-topic questions that don't have answers in the current FAQ file, but should. You may create new articles and then re-assign these queries to them. Thus, the "to-do" name. |
| Greeting | Enables the bot to initiate a conversation with the user. The bot will send the text of the Answer of this article to the user, unprompted |
The bot supports only English. It includes a language identification algorithm. When it detects a non-English query it returns the respective answer. (You can edit it.)
Currently, there are no classifiers for "Garbage", "Ignore" and "To do". The bot will NOT return "No results" response. However, when your users ask such questions you should still put them in these three classes. Otherwise, if you try to label these "bad" queries as legitimate it will wreak havoc on the algorithms. Additionally, Alterra may add the respective classifiers in the future. Your training corpus will be ready.
The pre-defined "Greeting" class is to initiate a conversation with the user. You may want your bot to be active and begin talking first, even if not prompted by the user. This pre-defined class is reserved for this purpose.
By default, the Alterra Bot is pro-active. After 20 seconds, it will open the web widget and greet the user with the “Hi! We'll be happy to answer your questions” message.
If you want a different greeting, you may edit it via the Edit tab.
You may also change the timeout or disable the active pop-up altogether. This will make the bot passive: it will wait until the user asks the first question. To do that, edit the parameters in the JS code you insert in your web pages.
Pre-defined articles are editable and can be manually deleted from your corpus.
Settings Tab
The Settings tab allows you to:
- Import and export your data
- Link your Facebook Page to enable chat in Facebook Messenger
- Combine your main FAQ corpus with pre-defined common corpora.
Training corpus upload
For the system to work, you have to first give it a training corpus. It should consist of:
- The FAQ file – the set of canonical question-answer pairs
- Historic user queries with the correct answers assigned to them
You can upload your FAQ file and query log to the system via FAQ Editor. Select Setting tab and click on the “Upload your FAQ” and “Upload your query log” buttons. You can upload your data in plain text (CSV) or JSON formats. (Alternatively, you can do it programmatically, via FAQ API or Phraser API.)
Plain text upload
FAQ file CSV format
Your FAQ file shall be in a coma-delimited CSV format
| ID | Question | Answer | Snippet |
|---|---|---|---|
| 1 | Do you offer a free trial? | Our products come with a free 30-day trial. Please go to our website and self-register. Your client ID and API key will be automatically created. If you have additional questions please leave your email here and we'll get back with you shortly. | Our products come with a free 30-day trial. |
| 2 | Send me more information | We will be happy to tell you more about our products and give you a demo. Please write to us at info@alterra.ai or just leave your email address here. | To receive more information, please write to us at info@alterra.ai or just leave your email address here. |
| 3 | How to train ML? | For the system to work, you have to first give it a training corpus. It should consist of historic user queries with the correct answers assigned to them. You can manually do it via FAQ Editor - see here how. You can also do it programmatically, via FAQ API or Phraser API. Upload as many historic queries as possible. The bigger the training corpus, the higher the search quality. | For the system to work, you have to first give it a training corpus. It should consist of historic user queries with the correct answers assigned to them. |
On every line CSV file has a string delimiter between its fields, which is comma.
If CSV field has comma inside, this field must be enclosed in quotation marks (Unicode symbol U+0022) (see Example 1). These quotation marks can’t be used as a symbol inside any field, but it’s possible to use other Unicode quotation marks, for example, right double quotation mark (U+201D).
Header is a first line in the CSV file. It must contain the names of the columns, which can be “id”, “question”, “answer” or “snippet”.
These columns can be located in any order.
Both “question” and “answer” columns must be present. But they could be empty.
Column “id” is optional. But due to API restrictions, if any line has non-empty “id” field, every other line must have “id” field being non-empty as well. “id” must be unique positive integer. Column “id” can be empty and is not required for successful import.
“Snippet” field is optional and is not required for successful import.
You may have more columns, with any name. They will be ignored.
HTML in answers. You may include rich text (HTML) in your answers. In FAQ Editor, copy-paste it from an HTML or rich-text file. The bot will display the rich text in the web widget. More here.
Example 1:
question, answer
“Hi, how are you?”, I’m fine. Thanks.
Do you have a free trial?, Our products come with a free 30-days trial.
Example 2:
id, question, answer, snippet
1, “Hi, how are you?”, I’m fine. Thanks., I’m fine. Thanks.
2, Do you have a free trial?, Our products come with a free 30-day trial., We offer a 30-day trial.
Query log text format
Upload historic user queries as a plain text file, with one query per line:
Hi, what are you doing?
I'm just wondering what this site does
So what's it you do?
Tell me about your company
What are you capable of doing?
What are you doing?
For the system to work, you have to label these queries, i.e. assign the correct answers to each of them. You do it after the upload. That is, you first upload unlabeled queries and then label them via the Label tab of the FAQ Editor.
JSON file upload
You may upload the entire training corpus as a single JSON file, containing both the FAQ file (the set of canonical question-answer pairs) and the already labeled queries (historic user queries with the correct answers assigned to them).
JSON file description
Each JSON object represents one Article, containing the ID, canonical question, answer, snippet and a list of queries assigned to it.
All JSON articles must have “question” and “answer” fields, which, however, can be empty. All other fields are optional.
“id” must be a unique positive integer. If any JSON article has non-empty “id” field, every other article must have “id” field being non-empty as well. “id” can be empty for all articles and it is not required for successful import.
Examples:
{
"question": "What is your address?",
"answer": "Our headquarters are in Palo Alto, California. Please contact us at info@alterra.ai",
"id": 3,
"queries": [
"What is your address?",
"Where is your company located?",
"are you based in palo alto?",
"company address pls",
"do you have an office in europe?",
"what's your address?",
"where are you based?",
"where are you from",
"where are you headquartered?",
"where are you located?",
"where are you?",
"where are your HQ?",
"where are your headquarters?",
"where is Alterra?",
"where is alterra located?",
"where is the company located?",
"where is your HQ?",
"where is your company based?",
"where is your headquarters?",
"where is your office located?",
"your address, please?"
]
},
{
"question": "Do you have API?",
"answer": "All our stuff is available via APIs. Details and API documentation <a href=\"http://next.alterra.ai/home/#api\" rel=\"nofollow
noopener\" target=\"_blank\"><< here. May I
have email to send more information to?",
"id": 9,
"queries": [
"API available?",
"Do you guys have an API?",
"Do you have a chat bot API?",
"Do you have an API?",
"Got API?",
"What are your apis?",
"What's your API is capable for?",
"api docs",
"api documentation",
"available over API?",
"do you have a REST API?",
"do you have api",
"do you have web api",
"how about api",
"is there an api?",
"what APIs do you have?",
"where can I find the API docs?",
"you have api"
]
}Common corpora
The Settings tab allows you to combine your main FAQ corpus with pre-defined common corpora.
The latter include question – answer pairs that are not specific to your FAQ file. They are rather universal. You have an option to add these common corpora to your main FAQ.
Currently, there are two common corpora available:
chitchat
Contains dialogs that would enable the bot to answer small talk questions like "how are you?", "are you a bot or a human?", "thank you, good bye", etc. You may view this corpus by clicking on the respective json or text links.
User queries related to these topics are independent of your knowledge base. They are common across all verticals. This engine comes with a collection of such common queries. The answers, however, are under your control -- you would edit the default values as you think fit.
grab_info
This corpus covers the "contact me" user intents. Currently, it contains only one article "contact me - here is my email address". Specifically, if the user message contains the user's email address this occurrence is detected by the bot. The bot will reply with the “Thank you. We will get back with you shortly.” message. (You may edit it in the Edit tab.)
Additionally, an email notification is automatically sent to you (to the email address you provided when registering at Alterra's website.)
When a common corpus is merged, it adds a set of articles to your FAQ. Merged articles are editable.
If a common corpus is un-merged, all its articles will be removed from the main FAQ, with all its attached queries. If you had added a corpus, edited it and then un-merged it you will lose all your edits.
Misc.
You may also export your data via the Settings tab.
The tab also displays your client ID and API key (should you need one). They are automatically generated when you self-register for the service on Alterra's website.